作者介绍
张帆,北京大学遥感与地理信息系统研究所助理研究员。2017年在香港中文大学获得博士学位;2015-2016年在麻省理工学院Senseable City Lab访问;2013年在联合国亚太经社委员会实习。
内容导读
城市中最有代表性的场景和物体是哪些?如何度量城市之间视觉环境的相似性?本研究利用数百万张来自于北京、东京、巴黎、旧金山等全世界18个城市的社交媒体照片,并基于计算机视觉和深度学习技术回答上述问题。研究结果发现,城市最有特色的物体不止于标志性建筑,还包括历史遗迹、宗教符号、特色街道风格、特色地貌等;类似地,本方法还支持对城市特色物体的提取,以车辆为例,研究发现城市中最有特色的车辆为出租车、巴士等交通工具。本研究适用于多种尺度(街道、城市、地区等)的场所(Place)物理环境之间分析,为场所形式化、城市视觉环境的定量研究提供方法支撑,为城市设计、规划和管理等领域提供决策支持。论文于2019年3月发表于Royal Society Open Science。
土耳其,东京,还是巴黎 ?

实验数据
本研究数据来自于Panoramio照片分享网站。如表1所示,照片来自于16个国家的18个城市,总数超过200万张;同时利用基于计算机视觉的物体检测识别模型,裁切出原始图片中的物体,共计80类,其中数目最多的物体类别为小轿车(car), 人(person),卡车(truck)等。
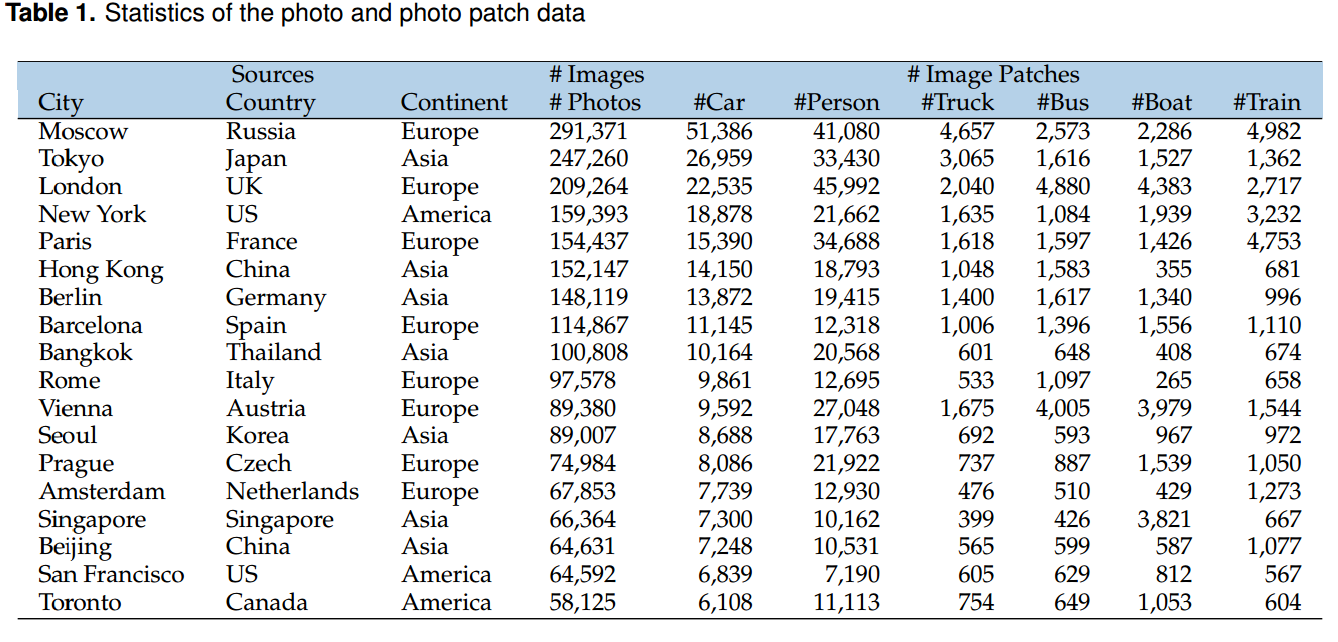
研究方法
方法主要分三个部分,如图1所示,第一部分,通过训练以城市为类别标签的图片分类模型,使模型学习每个城市视觉环境的内在表征(Learning deep representations)。第二部分,通过模型对全部样本的判别,得到城市类别间的混淆矩阵,计算城市特异度和相似度(若来自于两个城市间的样本相互识别错误率较高,则认为两城市较相似;若某个城市较不容易识别为其他任何城市,则认为某城市特异度较高)。第三部分,通过模型对全部样本的判别,将正样本(True positive samples)的置信度进行排序,取置信度较高的样本,作为最有城市特征的城市场景图片和城市物体图片(置信度反映了模型对某个样本属于某个类别的置信程度;拥有较高置信度的样本被认为最具有类别代表性)。
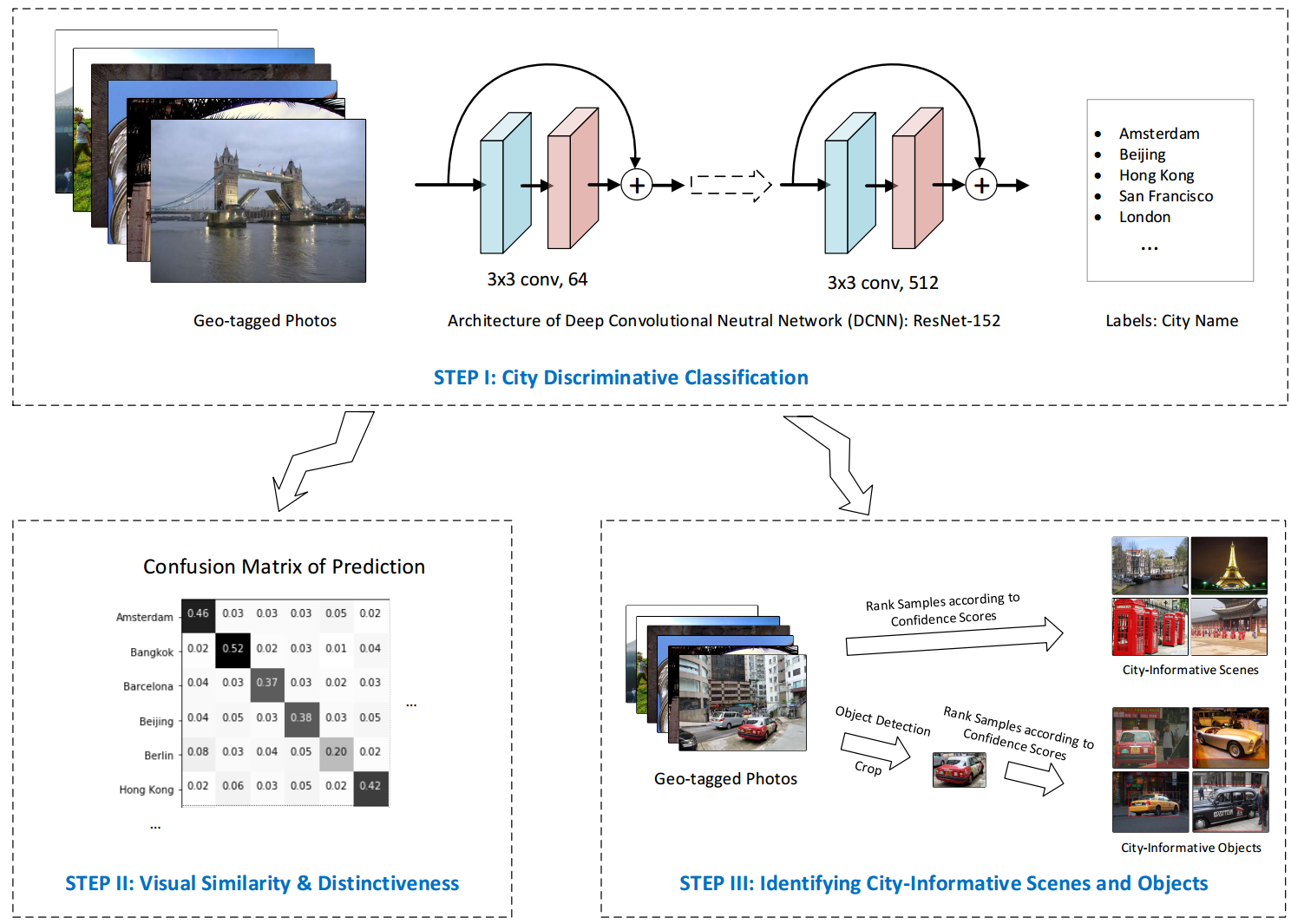
图1. 方法总体框架: I. 基于深度学习的图片分类(以城市为标签); II. 混淆矩阵分析; III. 基于置信度的样本排序
实验与结果分析
实验基于152层的ResNet模型,在200多万张图片的18个城市分类任务中取得了36.43%的准确度。图2所示为全球18个城市间的视觉环境相似度与特异度,其中较相似的城市用蓝色线连接,蓝色数字代表相似度分值;红色点大小代表了城市视觉环境的特异度,黑色数字代表特异度分值。例如,曼谷、罗马、首尔等的城市景观呈现出较高的特异度;伦敦和巴黎、布拉格和维也纳、罗马和巴塞罗那、新加坡和香港等两两城市之间具有较高的相似度,验证了方法的有效性。北京、东京、旧金山之间也有一定的相似性,原因有待进一步验证。
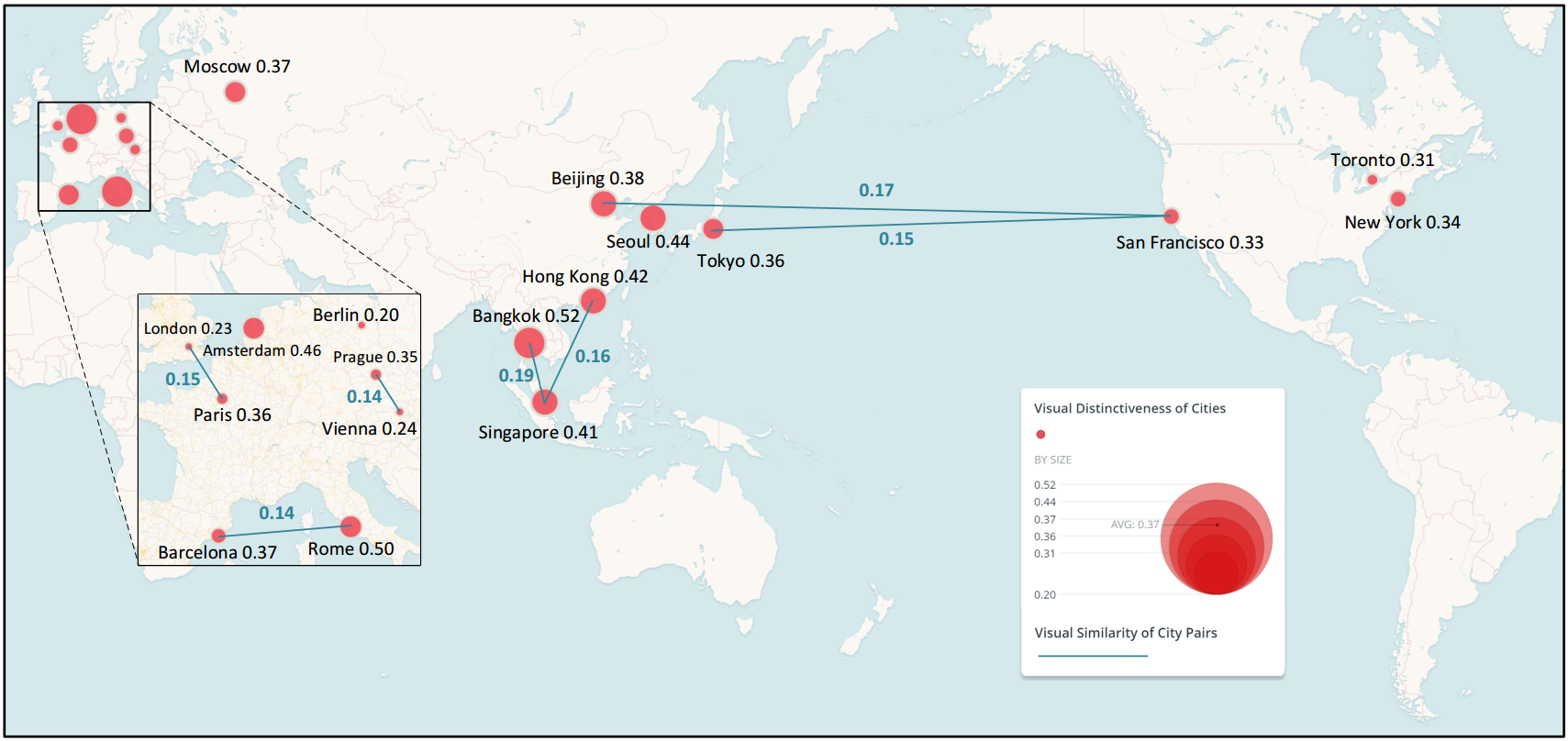
图2. 全球18个城市间的视觉环境相似度与特异度
图3所示为18个城市中每个城市的最有代表性的街景。例如,阿姆斯特丹、巴塞罗那、柏林、香港、莫斯科、布拉格和维也纳等城市表现出了极具特色的建筑风格;北京、罗马、首尔和东京等城市的街道呈现出特色的历史和文化符号;此外,结果中还发现了伦敦、巴黎和旧金山等城市的标志性建筑,例如伦敦桥、伦敦红色电话亭、埃菲尔铁塔、金门大桥等,展现出了城市代表性场景的多样性和方法的有效性。
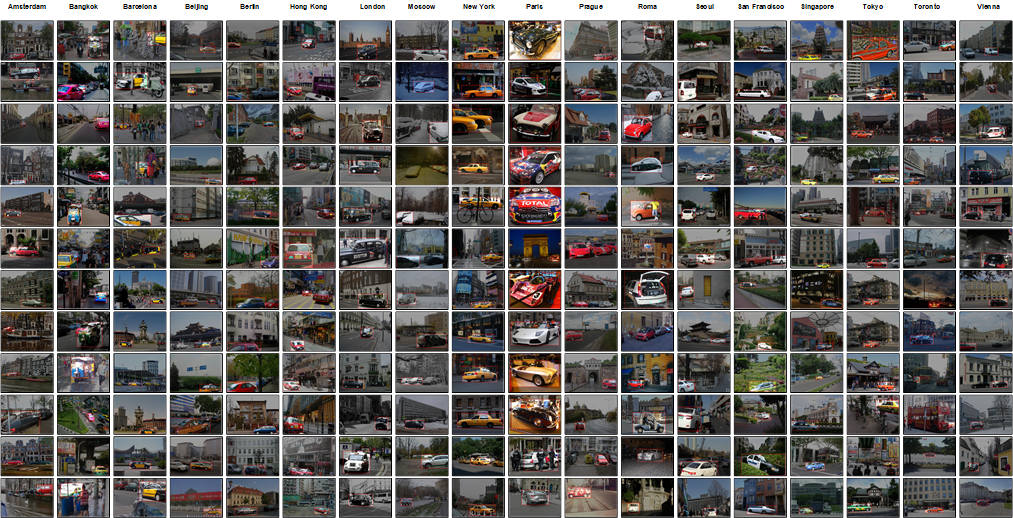
图3 城市最有代表性的场景

图4 城市最有代表性的物体 – 以车辆为例
图4所示为18个城市中每个城市的最有代表性的车辆。研究发现出租车、警车、救护车等公共车辆,由于涂装的城市内一致性和城市间的差异性,成为了城市最有代表性的车辆。其中,实验在曼谷、香港、东京等城市中识别出了两种以上的出租车。此外,伦敦街头的车辆以老式、复古型居多,罗马的车型一般较为紧凑,而巴黎的车辆比较奢华酷炫。
总结
移动互联网技术、导航定位技术和众包平台的发展带来了海量的、描述城市物质空间的街景数据,为城市空间的研究带来了潜在的机遇;而传统图像处理方法对于图片数据的分析能力有限,对街景数据中描述的城市复杂场景的理解能力不足。本研究利用社交媒体照片来刻画城市视觉环境,基于深度学习和计算机视觉技术学习城市视觉环境的深层次特征,提出了一个城市视觉环境间量化比较的分析框架,为场所物质空间、建成环境的定量研究提供支持,为城市设计、规划领域提供参考。
文献
[1] Fan Zhang, Bolei Zhou, Carlo Ratti, Yu Liu. Discovering place-informative scenes and objects using social media photos. Royal Society Open Science. 2019.03, 6(3) http://doi.org/10.1098/rsos.181375
[2] Fan Zhang, Bolei Zhou, Liu Liu, Yu Liu, Helene H. Fung, Hui Lin, Carlo Ratti. (2018). Measuring human perceptions of a large-scale urban region using machine learning [J]. Landscape and Urban Planning, 80, 148-160. https://doi.org/10.1016/j.landurbplan.2018.08.020
[3] Fan Zhang, Ding Zhang, Yu Liu, Hui Lin. (2018). Representing place locales using scene elements [J]. Computers, Environment and Urban Systems, 63, 58-67. https://doi.org/10.1016/j.compenvurbsys.2018.05.005
邮编:
通讯/办公地址:
邮箱:

北京大学遥感所

未名时空公众号



