内容导读
随着互联网的蓬勃发展以及大数据时代的到来,传统的关系型空间数据库已经不能很好地适应于超大规模高并发空间查询访问的处理需要。Spark是Hadoop生态系统中的新的优秀的分布式计算处理框架,得益于其独特的内存计算和惰性求值的优势,计算性能上较原先的MapReduce框架有了很大的提高。
作者着眼于解决大数据时代下地理信息服务所面临的日益严峻的大规模空间查询访问需求,探索了一套基于Spark架构的空间查询实现技术,并实现了一个基于NoSQL存储、Spark分布式内存计算并提供类SQL访问接口的空间查询处理框架GeoSpark SQL。GeoSpark SQL在初步实验中,已可以满足实时性的要求,对复杂的空间查询也能有良好的性能表现,能有力支撑大规模地理数据在线请求和分析的计算需求。融合SQL与NoSQL优点的NewSQL是的大数据时代数据库系统发展的最新趋势,GeoSpark SQL可以视为迈向NewSQL的未来空间数据库雏形。
研究内容
GeoSpark SQL实现了以下关键方法:①存储管理:通过Hive/Spark实现对空间数据的NoSQL存储管理,包括外包矩形索引模块和数据导入导出模块;②空间查询算子:通过扩展Spark的用户自定义函数(User Defined Function, UDF)后,可以在对Spark的查询中使用包括相交、分离、9交判断等空间查询算子;③空间查询处理加速:为空间数据处理提供特殊优化的加速手段,包括使用空间索引和地理要素本地反序列化缓存进行查询加速。
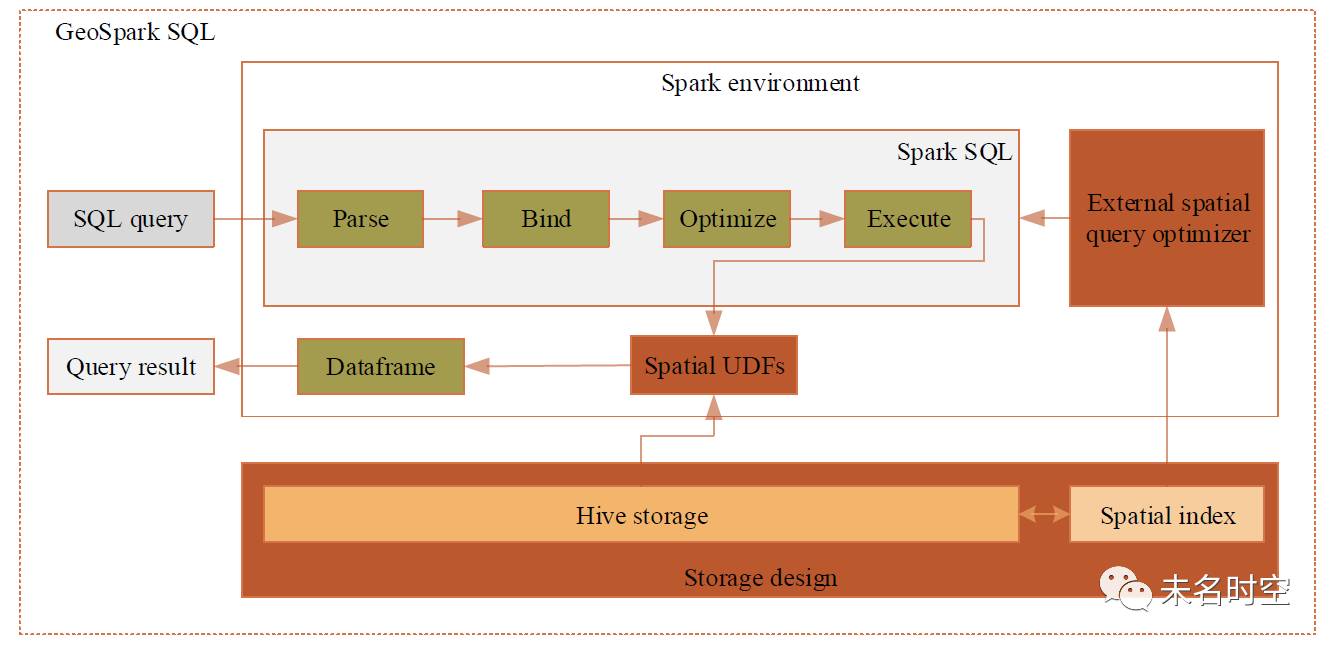
图1 GeoSpark SQL框架
研究成果分析与讨论
将GeoSpark SQL部署于美团云集群计算环境,并按照属性查询、k最近邻(k-Nearest Neighbor, kNN)查询、点查询、窗口查询、范围查询、方位查询、拓扑查询、多表空间连接查询等类别分别设计了一组查询用例,实验将GeoSpark SQL的空间查询性能与PostGIS/PostgreSQL、ESRI Spatial Framework for Hadoop做了详尽的比较。GeoSpark SQL已可以满足实时空间查询的要求,尤其对复杂的空间查询(如kNN/拓扑/空间连接查询)有着更加优异的性能表现。
表1 实验结果数据表(单位:毫秒)
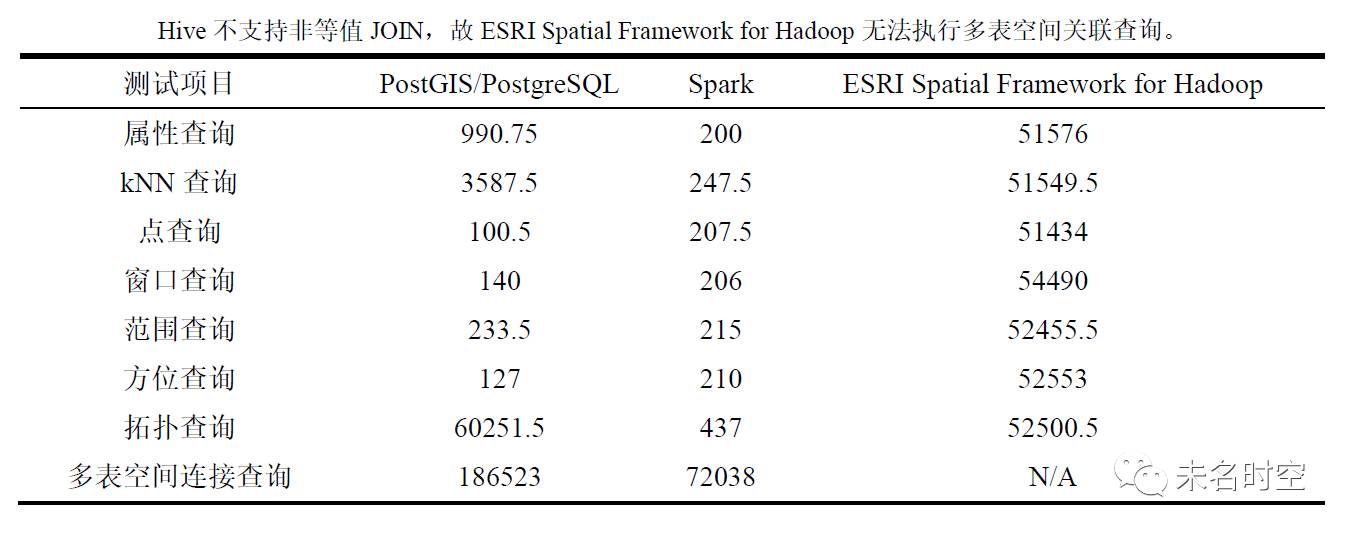
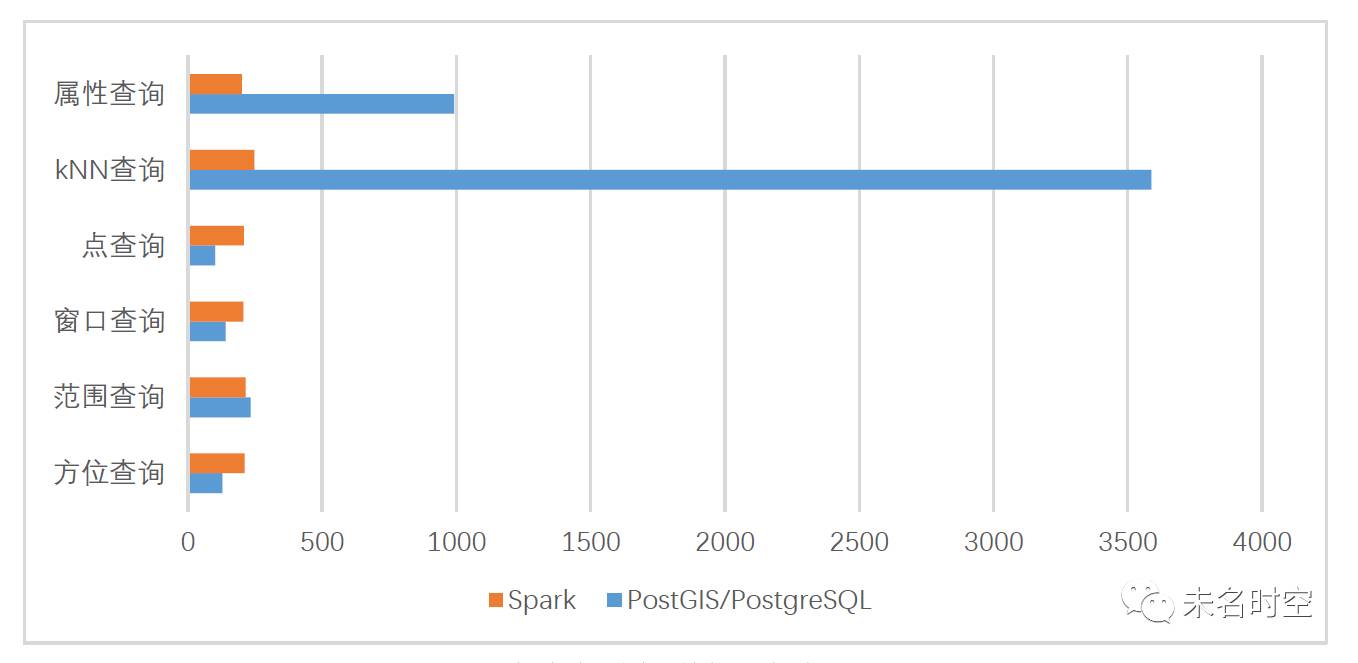
图2 实验结果图(单位:毫秒)
由于ESRI Spatial Framework for Hadoop的时间普遍在50秒以上,为对比明显,故不绘入结果图中;拓扑查询、多表空间关联查询的实验结果同理。
结论
本文成功在Spark/Hive分布式计算环境下完成了一套空间查询原型系统GeoSpark SQL,经过初步验证后功能正确,性能可以满足实时查询的要求,在kNN和多表空间连接等需要较多计算资源的查询中表现出色。
基于Spark/Hive构建空间数据库系统有如下几个优势:(1)数据库可横向扩展:数据量增加情形下可以通过增加机器来加快响应速度;(2)系统更健壮:Spark是成熟的分布式处理系统,在其上搭建的GeoSpark SQL能够利用Spark本身的健壮性来保证空间数据的高性能计算;(3)能够以更高的效率支持新的功能和需求:SQL接口易于使用,强大的计算效率也可以有效支撑新功能和需求。因此,使用Spark/Hive开发空间查询系统,相较传统的数据库有更大的优势,能够以更敏捷的速度面对变化的需求,更强的健壮性和容错性支持需求。
参考文献
Huang, Z.; Chen, Y.; Wan, L.; Peng, X. GeoSpark SQL: An Effective Framework Enabling Spatial Queries on Spark. ISPRS Int. J. Geo-Inf. 2017, 6, 285; doi: http://dx.doi.org/10.3390/ijgi6090285.
素材来源:S3-Lab
材料整理:陈逸然
内容排版:龚旭日

邮编:
通讯/办公地址:
邮箱:

北京大学遥感所

未名时空公众号



