摘要:借助空间聚类的手段可以发现环境中事件和要素的空间分布模式。而通过对海量点集数据做空间聚类,发现人类活动的自然边界,是地理大数据分析中寻找热点、生成新型空间研究单元的新思路。手机/出租车轨迹点、微博签到、带地理标签的图片等数据在各种大数据研究中被广为使用,传统聚类方法与工具在海量数据计算、自适应聚类等方面已不能很好地满足分析需求,迫切需要我们研究针对于地理大数据中海量点集的高性能聚类算法和工具。
因此,我们通过将前人提出的寻找聚类中心的思路,与我们在百万量级乃至千万量级的点数据聚类实践进行结合,并且①引进了DBSCAN通过密度归类的方法,②使用了CPU与GPU进行加速,最终开发了一个新的面向海量点集的空间聚类工具HiSpatialCluster,有效解决了大数据环境下海量点集的高效、自适应聚类问题。该工具为ArcGIS插件,便于空间分析研究人员使用。
国内外进展
空间聚类分析的手段有很多,一般可以将聚类算法分为七类(Deng et al., 2011),分别是基于划分的算法,基于层次的算法,基于密度的算法,基于图的算法,基于模型的算法,基于格网的算法和其他的混合的算法。
表1 七类空间聚类算法简述
具有空间聚类功能的工具如CLUTO、Weka等,包含了许多空间聚类算法,体系也较为完整。基于Python语言的scikit-learn包中也有如K-means、DBSCAN等常用的空间聚类算法。但是,一方面,大数据场景下的空间点集规模巨大,这些现有软件工具难以支撑百万量级及以上数量级的聚类计算。另一方面,常用的K-means、DBSCAN等聚类算法也存在一些缺点:如K-means无法发现非球形的聚类;各类聚类算法对空间密度分布不均的点集聚类效果不佳,无法实现自适应聚类。
研究方法
Rodriguez and Laio (2014)提出了一种较为稳健和自适应的聚类算法CFSFDP(Clustering by fast search and find of density peaks),并且也适宜进行并行化加速和异构计算加速。基于上述实际应用中的问题,本文把CFSFDP的寻找聚类中心的思路与我们在百万量级乃至千万量级的点数据聚类实践进行结合,同时引进了DBSCAN通过密度归类的方法,开发了一个新的面向海量点集的空间聚类工具HiSpatialCluster。HiSpatialCluster已经通过github对外发布(https://github.com/lopp2005/HiSpatialCluster)。该工具既可以使用CPU并行加速计算,也可以使用GPU进行加速计算。该工具一方面解决密度分布不均情况下的自适应聚类问题,另一方面按密度相连过滤的方法使得聚类结果(热点区域)的形状与现实很好地相符;此外,还通过GPU计算解决了海量点集的聚类问题。
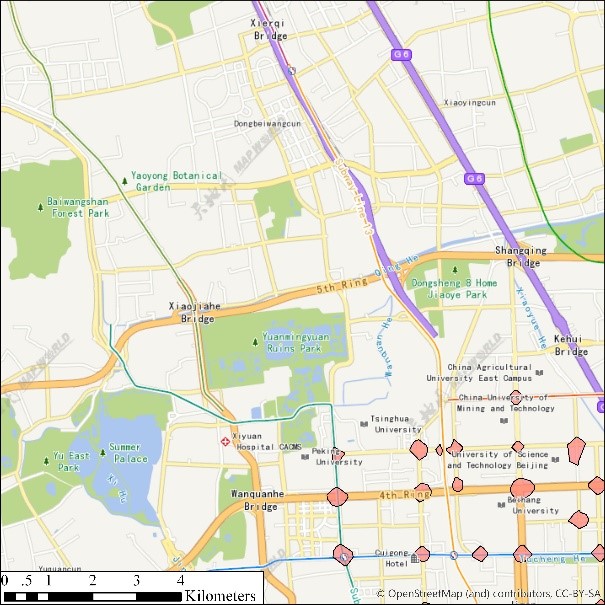
不同时间段的出租车轨迹点具有不同的分布和数据量,我们对每天2点和12点后5分钟内的出租车轨迹点进行聚类的结果,体现出了软件对于不同数据分布和不同数据量的空间聚类结果的稳定性和可靠性。我们选取了北京海淀部分区域和北京全局进行可视化。可以看出,由于不同的数据分布,识别出的区域并不相同,且密度大的地方区域较小,密度小的地方区域较大。类别的高密度中心也能够很好地被识别出来。而k-means和DBSCAN并不具备这些优势。

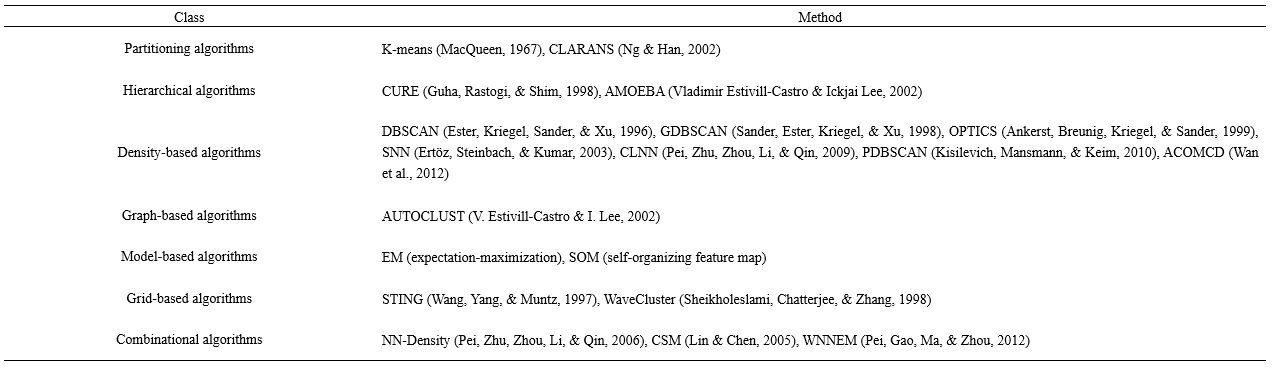
(a) Clustering result by HiSpatialCluster (2:00-2:05 am) (b) Clustering result by K-means (2:00-2:05 am)
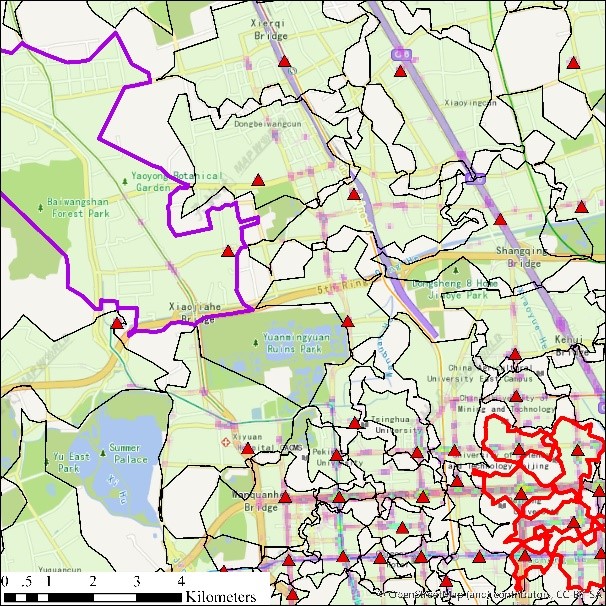
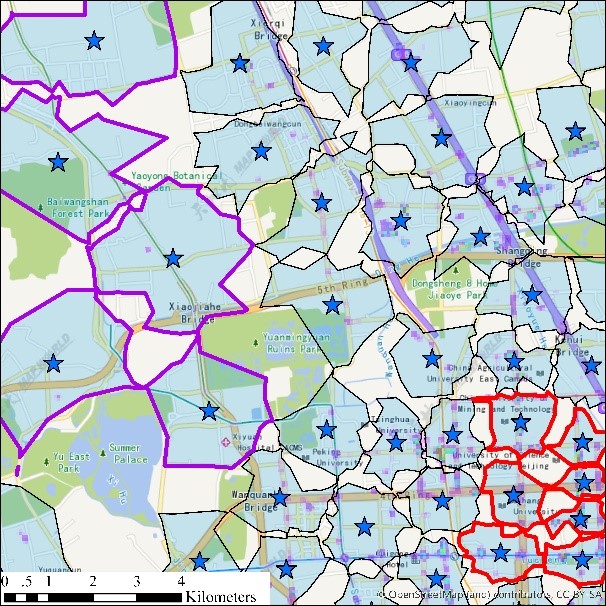
(c) Clustering result by HiSpatialCluster (12:00-12:05 am) (d) Clustering result by K-means (12:00-12:05 am)

图1 出租车轨迹点K-means与HiSpatialCluster聚类结果对比
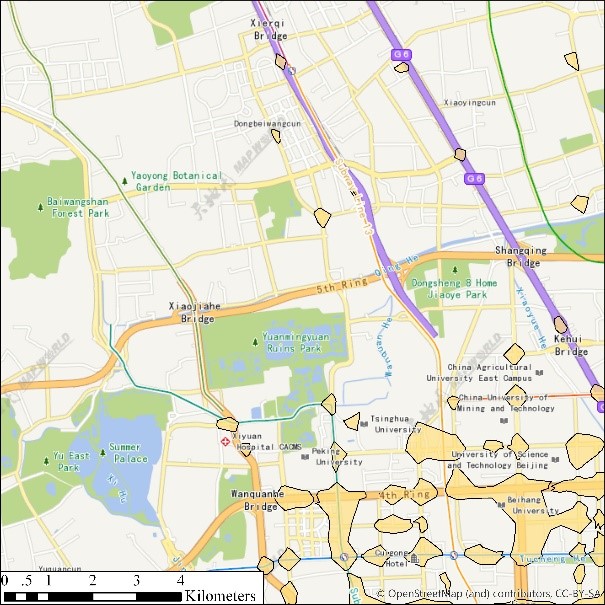
(a) eps = 100, minpts=500 (b) eps=100, minpts=200
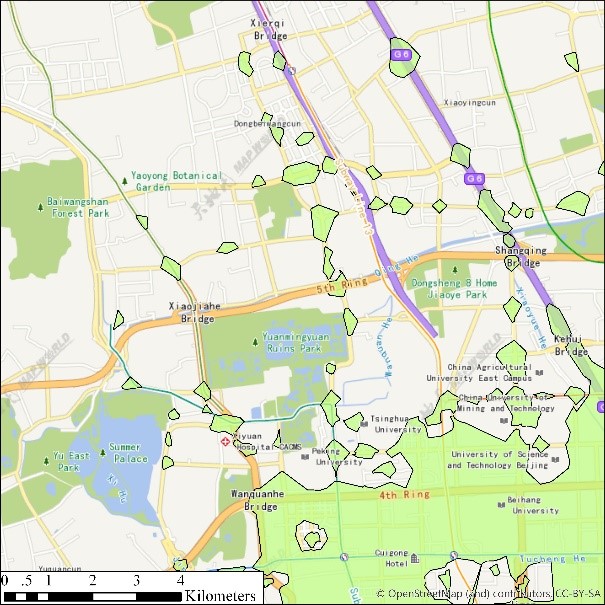
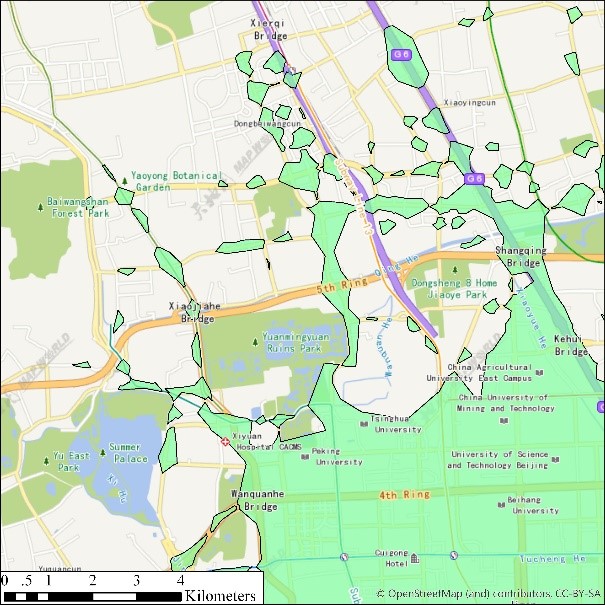
(c) eps=100, minpts=100 (d) eps=100, minpts=50
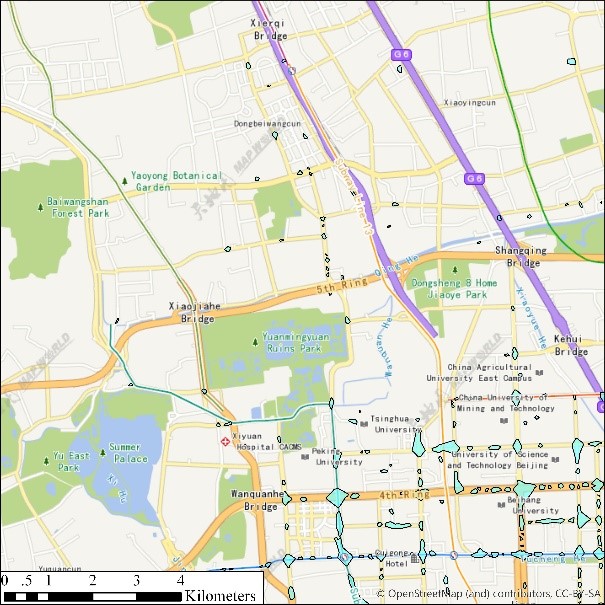

(e) eps=30, minpts=50 (f) eps=30, minpts=20
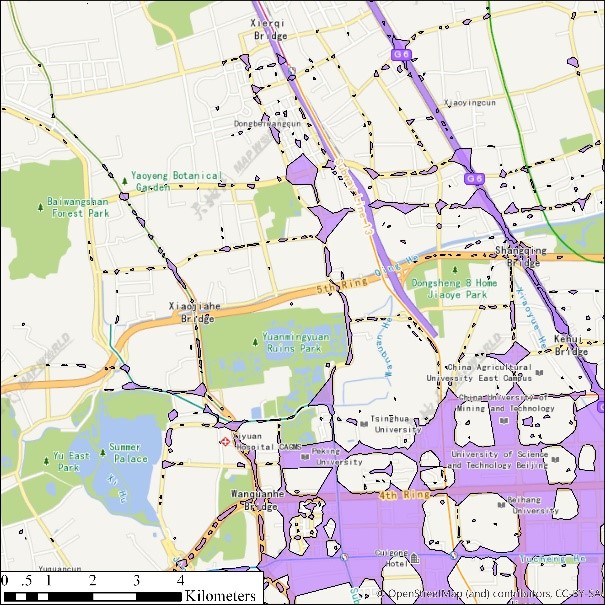
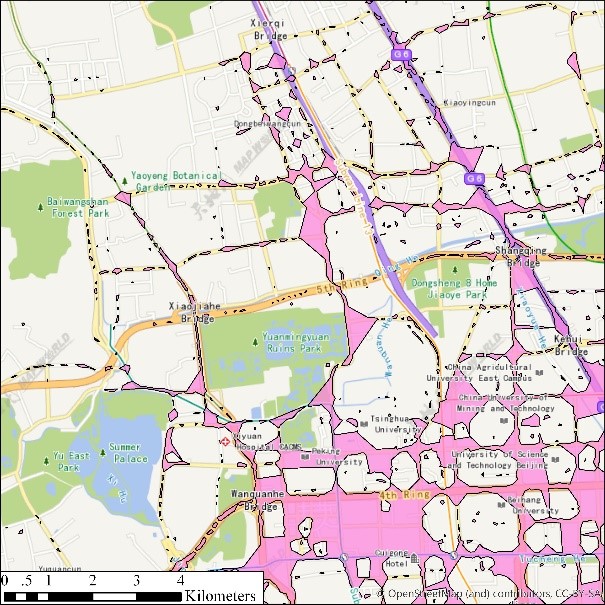
(g) eps=30, minpts=10 (h) eps=30, minpts=5

(i) Legends
图2 出租车轨迹点(12:00-12:05am)DBSCAN聚类结果展示
研究结果
我们选取了7组数量不同的测试数据,以评估聚类的速度。测试的硬件平台是intel core i7-4770, 32g memory, 3t hard disk, with GTX 1080Ti *1。对比测试工具为ArcGIS中Grouping Analysis工具。测试的数据量级别为10k~1m,对于2m及以上的数据,K-means已经无法在arcgis规定的100次循环内完成收敛,故没有测试2m及以上的数据集。可以看到,GPU加速始终可以在非常快的时间内完成聚类,CPU加速也能够在数据量较小时表现出出色的成绩。二者所耗费的时间与数据量大小的关系十分稳定。从实验结果表中看出,由于HiSpatialCluster的时间复杂度为O(n2),所以以K-means所耗时间为基准,CPU在数据量较小时加速比较高,在数据量大时加速比略有下降;而由于GPU强大的计算效率,使得GPU加速的HiSpatialCluster获得了可观的加速比。
表2 不同聚类工具速度对比
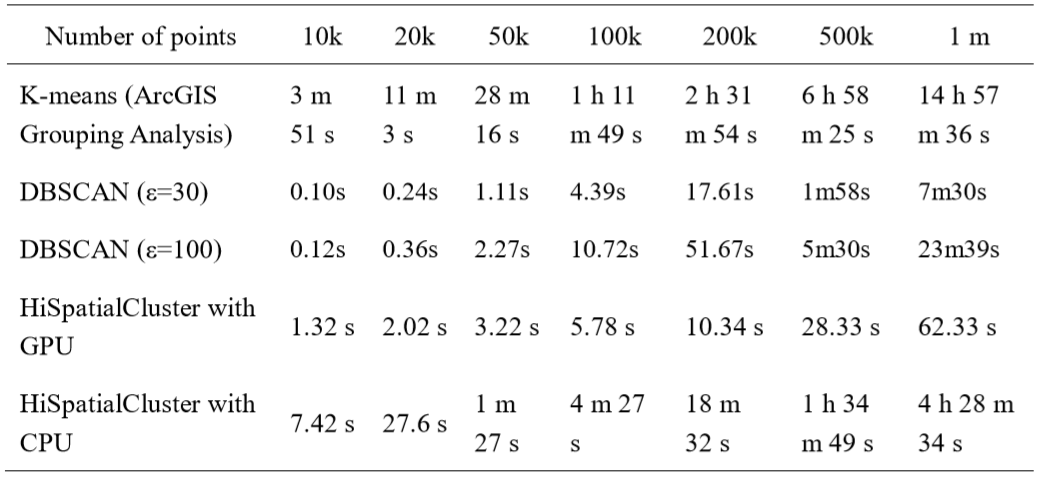
表3 超大空间点数据集下HiSpatialCluster GPU聚类速度 
研究结论
我们通过将CFSFDP的寻找聚类中心的思路,与我们在百万量级乃至千万量级的点数据聚类实践进行结合,并且①引进了DBSCAN通过密度归类的方法,②使用了CPU与GPU进行加速,最终开发了一个新的适用于大数据环境、面向海量点集的空间聚类工具HiSpatialCluster。HiSpatialCluster具有如下优势:①稳定和鲁棒:算法不依赖初始值和计算顺序,能稳定地反映数据分布规律和趋势。密度相连过滤能帮助提取聚集区域。②快速地完成海量点数据聚类:由于实现了CPU并行加速和GPU加速,能够在极短的时间内完成百万及以上量级的点数据聚类。
参考文献
Yiran Chen, Zhou Huang, Tao Pei, Yu Liu. HiSpatialCluster: A novel high‐performance software tool for clustering massive spatial points. Transactions in GIS. 2018;22:1275–1298. https://doi.org/10.1111/tgis.12463.
备注:微信公众号文章阅读原文请链接到https://doi.org/10.1111/tgis.12463
邮编:
通讯/办公地址:
邮箱:

北京大学遥感所

未名时空公众号



