导读
随着定位技术的发展和移动设备的广泛使用,海量的带有位置信息的数据正源源不断地产生,数字轨迹便是其中的一种。人们在物理空间的移动被可获取位置的终端和应用记录下来,形成了个人的数字轨迹。现有研究表明,个体轨迹模式和个体属性(如收入水平、受教育程度等)有很强的相关性。鉴于个体属性对许多领域具有重要价值但不易获取,由轨迹推断属性引起了关注。在本研究中,我们提出了一个从个体轨迹中构建特征的框架,并将该框架应用于个体属性预测。实验结果表明,该特征框架达到了较好的属性预测准确度。实验结果表明,该框架达到了较好的属性预测准确度。
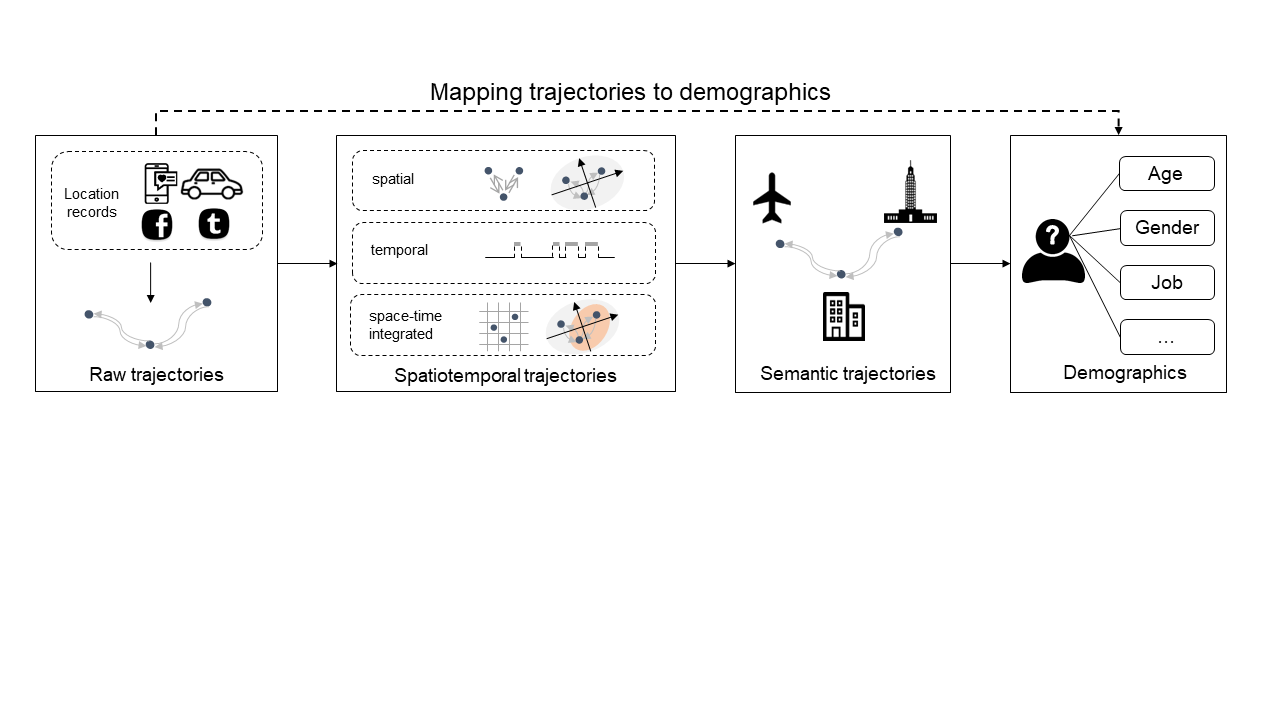
图1 基于个体轨迹的用户画像示意图。首先,从位置记录中提取原始轨迹,接着构建时空特征和语义特征,最后将特征输入到机器学习模型进行属性预测。
特征框架旨在提取轨迹模式。如表1所示,轨迹特征分为两大类:时空特征和语义特征。
时空特征旨在捕捉轨迹在空间和时间上的模式,不同人在时空上的移动模式具有差异。时空特征包括空间特征、时间特征和时空耦合特征。其中,空间特征又包括一阶点层次、二阶线层次和高阶Motif层次。点层次特征基于独立的停留点计算,反映停留点的异质性、空间范围和形状指数;线层次关注两点间的出行特征,包括出行次数、出行熵和出行距离;Motif层次刻画了所有停留点形成的结构。时间特征反映了人们的出行和停留的碎片化程度和出行的时间规律性。时空耦合特征融合了空间和时间,包括前K个停留点的回转半径、前2个高频点的坐标以及停留点在人群轨迹中的独特性。
语义特征旨在提取人们所进行的活动,不同人所进行的活动类型和占比不尽相同。活动类型可由轨迹背后的地理环境承载的功能反映,比如当停留点所处的位置是商城时,个体很可能在进行购物或娱乐活动。因此,将轨迹和用地类型做叠加,可以挖掘个体所进行的活动。
考虑到工作日和周末个体出行模式有所差异,在进行特征计算时,分别计算各个特征在工作日、周末和总体上的平均值和标准差,作为特征向量的元素。
表1 轨迹特征

轨迹数据来自于居住或工作于北京上地清河地区的709名志愿者。志愿者被请求携带GPS记录器7天。由于GPS位置涉及到个人隐私,在实验开始前,我们制定了隐私保密协议提供给志愿者,志愿者同意并签署后,其数据方可被使用。GPS记录的空间分辨率是15m,时间分辨率是30s。由于GPS信号丢失、志愿者忘记携带记录器等原因,部分志愿者的轨迹无法使用。经过滤,有437名志愿者的轨迹记录完好,其停留点分布如图2所示。

图2 停留点分布和轨迹示例。停留点数目指所有参与者在500m格网内的停留点个数。轨迹示例是一位参与者在实验期间内的轨迹。
用地类型数据
用地类型数据由北京市规划部门发布,空间分辨率为30m。共有12类,如图3所示。

图3 用地类型
属性数据
属性信息包含5种:性别,年龄,婚姻状况,受教育水平,居住类型。其数量分布如表2所示。
表2 属性信息

以Motif和出行节律(travel rhythm)两个特征的统计结果为例进行说明。
对于Motif,在1%的阈值下共有9个motif,总占比达到94.4%,如图4(a)所示。停留点数目从1-4,占比最高的为两点的motif。结构上,有链条型、单环型、环状-链条型以及双环型。任意选取两个参与者的motif特征,如图4(b)所示,可以发现他们的motif组成不尽相同。对于出行节律,如图4(c)所示,参与者#0在7.00-8.00和16.00-17.00出行频率较高,而参与者#1在7.00-8.00和18.00-19.00出行频率较高,两者的出行节律有所差异。观察两个参与者的属性,他们相同的属性有婚姻状况、居住类型和年龄段,不同的属性在于性别和受教育程度。从统计结果很难直接得出哪种属性的不同导致了其轨迹特征的差异,其潜在的关系需要通过机器学习算法挖掘。

图4 Motif和出行节律的统计结果。(a)Motif 集合。N表示motif的停留点个数,motif上面的百分比代表其出现的频次。(b)两个参与者的motif分布。横轴的“Motif ID”与(a)中的ID编号对应。(c)散点图表示两个参与者(与(b)中的参与者相同)在工作日的出行节律,线图表示所有参与者在工作日的平均出行节律。
根据提出的特征框架,将每个个体的轨迹转化为特征向量,输入到分类算法中,进行属性预测。对于分类算法,我们测试了SVM、Random Forest和XGBoost三种方法,取综合表现最好的XGBoost作为最终的分类器,其预测结果如图5所示。当输入所有特征时,最高准确度可达82%。不同类型特征的预测能力有所不同,对于时空特征下面的空间、时间和时空耦合特征而言,时间特征对于性别和居住类型有较强的揭示能力,而年龄、受教育程度和婚姻状况更容易由时空耦合特征推断。语义特征整体上没有时空特征的揭示能力强,这与用地类型所指代的活动的模糊性有关。尽管不同类型特征对属性的预测能力不同,但总体上,特征的组合能够带来更好的效果。

图5 属性预测准确度
为了理解特征的不同如何对预测起作用,我们根据重要性分数,提取了对每个属性预测的最重要特征,将其分布进行可视化。如图6所示,对婚姻状况和居住类型揭示能力最大的是用地类型,具体指停留时长排在第二位的停留位置的商业用地面积占比。对于该位置的商业类型面积占比,已婚群体平均小于未婚群体,当地居民平均小于外来人员。对受教育程度而言,出行熵即在各个时间段出行频次的熵值对预测的贡献度最大,有大学教育背景的群体具有较低的出行熵,即相对于无大学教育背景的群体,其出行更加规律。对于年龄和性别,在工作日18:00-21:00的出行频次和周末的日停留点数目分别贡献最大,但其在不同属性群体的分布差异并不太明显,这也解释了年龄和性别预测准确度较低的现象。

图6 预测贡献度最大的特征在不同属性群体中的分布
本研究提出了一个轨迹特征提取的框架,并将其应用于属性预测,达到了良好的预测准确度。在地理大数据时代,个体轨迹被大量记录,地理背景信息也日益丰富。本研究可为多个领域提供有价值的参考。比如对于涉及位置服务的企业,本研究可以帮助企业更好地了解用户。对于未来的研究方向,语义轨迹的精准构建最为重要,现有研究中对轨迹语义的刻画还存在较大的模糊性,需要进一步探索。
邮编:
通讯/办公地址:
邮箱:

北京大学遥感所

未名时空公众号



